
Predicting customer churn from a telecom provider
I’ve always believed that to truly learn data science you need to practice data science and I wanted to do this project to practice working with imbalanced classes in classification problems. This was also a perfect opportunity to start working with mlflow to help track my machine learning experiments: it allows me to track the different models I have used, the parameters I’ve trained with, and the metrics I’ve recorded.
This project was aimed at predicting customer churn using the telecommunications data found on Kaggle (which is a publicly available synthetic dataset). That is, we want to be able to predict if a given customer is going the leave the telecom provider based on the information we have on that customer. Now, why is this useful? Well, if we can predict which customers we think are going to leave before they leave then we can try to do something about it! For example, we could target them with specific offers, and maybe we could even use the model to provide us insight into what to offer them because we will know, or at least have an idea, as to why they are leaving.
Performance vs Interpretability
It’s very important to know and understand the problem/task at hand before we start to even think about writing any code. Would it be useful in this case to build a really powerful model like XGBOOST? No, of course not. Our goal isn’t to squeeze every drop of performance out of our model. Our goal is to understand why people are leaving so we can do something about it and try to get them to stay. In an ideal world, we would build a very interpretable model, but in reality, we may have to find a happy medium between performance and interpretability. As always, logistic regression would be a good start.
Model Evaluation
We now need to decide how we are going to evaluate our models and what we are going to be happy with. I think it’s important to decide an end goal beforehand as otherwise, it’s going to be hard to decide when to stop, squeezing out those extra 1%s is not worth it a lot of the time.
Due to the nature of our data, our classes are likely going to be highly imbalanced, with the case we are interested in (customers leaving) being the minority class. This makes selecting the right metric super important.

The metrics we are going to be interested in are precision, recall, and other metrics associated with these. Precision is the ratio of correct positive predictions to the overall number of positive predictions. Recall is the ratio of correct positive predictions to the overall number of positive predictions in the dataset. In our case we are looking at trying to retain customers by predicting which customers are going to leave: so we aren’t too fussed if we miss-classify some customers as ‘churn’ when they are not (false positives). If anything, these miss-classifications might be customers that would soon become ‘churn’ if nothing changes as they may lie on the edge of the decision boundary. So, we are looking to maximize recall as it will minimize the number of false negatives.
We are also going to look at the F-measure as it provides a way to express both concerns of precision and recall with a single score — we don’t just want to forfeit precision to get 100% recall!
Model Specifications
Once we have built our final model, we can then use a precision-recall curve to optimize our performance on the positive (minority class). In this case, we are going to assume that stakeholders in our imaginary telecoms business want to achieve a recall of 0.80 (i.e. we identify 80% of the positive samples correctly) while maximizing precision.
Data
train.csv— the training set. Contains 4250 rows with 20 columns. 3652 samples (85.93%) belong to class churn=no and 598 samples (14.07%) belong to class churn=yes.test.csv— the test set. Contains 850 rows with 18 columns.
import pandas as pd
from src.data.load_data import read_params
# load in training data
config = read_params("params.yaml")
external_data_path = config["external_data_config"]["external_data_csv"]
df = pd.read_csv(external_data_path, sep=",", encoding="utf-8")
# check we have our 20 cols
assert len(df.columns) == 20
EDA (along with all the modeling etc.) was done in different python scripts and I have chosen to not include it here as it is irrelevant to the topic I am writing about. It is nonetheless very important and you can find this whole project on my Github page.
Due to the high cardinality of the state columns, we need to be careful when encoding them otherwise we will end up with 50 different features!
df.head()

We can look at a correlation matrix to see any initial promising features.
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="white")
# Compute the correlation matrix
corr = df.corr()
# Generate a mask for the upper triangle
mask = np.triu(np.ones_like(corr, dtype=bool))
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(230, 20, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
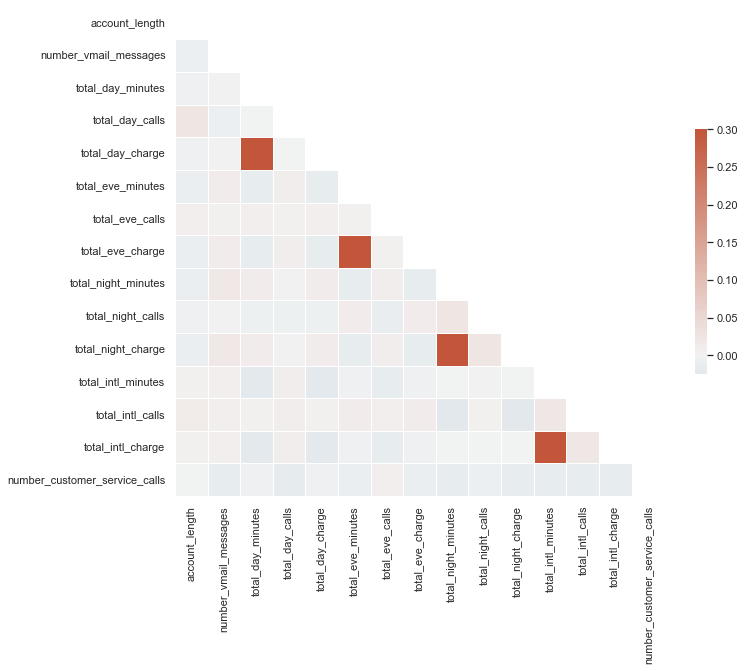
Ok, this doesn’t look great but we can see that churn is somewhat correlated with total_day_minutes, total_day_charge, and number_customer_service_calls. Let’s build a simple baseline model with total_day_minutes and number_customer_service_calls (we omit total_day_charge because it’s strongly correlated with total_day_minutes).
Feature Engineering
We can generate a few features to encapsulate daily totals. We also map the state feature to the regions the state belongs to as it massively reduces the feature dimensionality. Finally, we can map churn target value to binary as this is required for a lot of models.
def preprocess(df):
# add new features
df['total_minutes'] = df['total_day_minutes'] + df['total_eve_minutes'] + df['total_night_minutes']
df['total_calls'] = df['total_day_calls'] + df['total_eve_calls'] + df['total_night_calls']
df['total_charge'] = df['total_day_charge'] + df['total_eve_charge'] + df['total_night_charge']
# target mapping
target_mapping = {"no": 0, "yes": 1}
df.loc[:, 'churn'] = df['churn'].map(target_mapping)
# map state
state_mapping = {
'AK': 'O', 'AL': 'S', 'AR': 'S', 'AS': 'O', 'AZ': 'W', 'CA': 'W', 'CO': 'W', 'CT': 'N', 'DC': 'N', 'DE': 'N', 'FL': 'S', 'GA': 'S',
'GU': 'O', 'HI': 'O', 'IA': 'M', 'ID': 'W', 'IL': 'M', 'IN': 'M', 'KS': 'M', 'KY': 'S', 'LA': 'S', 'MA': 'N', 'MD': 'N', 'ME': 'N',
'MI': 'W', 'MN': 'M', 'MO': 'M', 'MP': 'O', 'MS': 'S', 'MT': 'W', 'NA': 'O', 'NC': 'S', 'ND': 'M', 'NE': 'W', 'NH': 'N', 'NJ': 'N',
'NM': 'W', 'NV': 'W', 'NY': 'N', 'OH': 'M', 'OK': 'S', 'OR': 'W', 'PA': 'N', 'PR': 'O', 'RI': 'N', 'SC': 'S', 'SD': 'M', 'TN': 'S',
'TX': 'S', 'UT': 'W', 'VA': 'S', 'VI': 'O', 'VT': 'N', 'WA': 'W', 'WI': 'M', 'WV': 'S', 'WY': 'W'
}
df.loc[:, 'state'] = df['state'].map(state_mapping)
return df
# preprocess dataframe and add features
df = preprocess(df)
df.head()
Modeling
The first thing that always needs to be done is to split the data into train and validation sets as it is a vital step to avoid overfitting, improve generalizability, and help us compare potential models. In this case, we use stratified K-fold cross-validation as our dataset is highly imbalanced and we want to ensure the class distribution is consistent across folds.
from sklearn.model_selection import StratifiedKFold
def stratKFold(df, n_splits=5):
"""
Perform stratified K fold cross validation on training set
:param df: pd dataframe to split
:param n_splits: number of folds
:return: df with kfold column
"""
# create new column 'kfold' with val -1
df["kfold"] = -1
df = df.sample(frac=1, random_state=42).reset_index(drop=True)
# target values
y = df['churn'].values
# initialise kfold class
kf = StratifiedKFold(n_splits=n_splits)
for f, (t_, v_) in enumerate(kf.split(X=df, y=y)):
df.loc[v_, "kfold"] = f
return df
df = stratKFold(df)
Baseline Model
We start by building a simple baseline model so that we have something to compare our later models to. In a regression scenario we could simply use the average of the target variable at every prediction, in our classification case however we are going to use a logistic regression model trained on our two most correlated features.
Before we start let's initialize Mlflow and write a general scoring function to evaluate our model.
import mlflow
from sklearn.metrics import f1_score, recall_score, precision_score
# initialize mlflow
mlflow.set_experiment("mlflow/customer_churn_model")
# scoring function
def score(y, preds):
"""
Returns corresponding metric scores
:param y: true y values
:param preds: predicted y values
:return: f1_score, recall, and precision scores
"""
f1 = f1_score(y, preds)
recall = recall_score(y, preds)
precision = precision_score(y, preds)
return [f1, recall, precision]
Now let’s build our baseline model and see how it does on each validation set!
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
# baseline model
f1_scores, recall_scores, precision_scores = [], [], []
for fold in range(5):
# define train and validation set
features = ["total_day_minutes", "number_customer_service_calls"]
df_train = df[df.kfold != fold].reset_index(drop=True)
df_valid = df[df.kfold == fold].reset_index(drop=True)
# target and features
y_train = df_train['churn'].values
y_valid = df_valid['churn'].values
# init and fit scaler
scaler = StandardScaler()
x_train = scaler.fit_transform(df_train[features])
x_valid = scaler.transform(df_valid[features])
# create and train model
clf = LogisticRegression()
clf.fit(x_train, y_train)
preds = clf.predict(x_valid)
# score model
scores = score(y_valid, preds)
f1_scores.append(scores[0])
recall_scores.append(scores[1])
precision_scores.append(scores[2])
# average scores over each fold
f1_avg = np.average(f1_scores)
recall_avg = np.average(recall_scores)
precision_avg = np.average(precision_scores)
print(f"Average F1 = {f1_avg}, Recall = {recall_avg}, Precision = {precision_avg}")
# log metrics on mlflow
with mlflow.start_run(run_name="lr_baseline") as mlops_run:
mlflow.log_metric("F1", f1_avg)
mlflow.log_metric("Recall", recall_avg)
mlflow.log_metric("Preision", precision_avg)
info
Average F1 = 0.08725, Recall = 0.04847, Precision = 0.44093
So yea, the results aren’t great (actually they are terrible) but that only means we are going to get better. This was only a baseline! We can try a few things to improve our model:
We can balance out our classes by over and under-sampling as the imbalance is causing bias towards the majority class in our model.
We can train on more features.
SMOTE: To Over-Sample the Minority Class
One problem we have with imbalanced classification is that there are too few examples of the minority class for a model to effectively learn the decision boundary. One way to solve this problem would be to over-sample the examples in the minority class. This could be achieved by simply duplicating examples from the minority class in the training dataset, although this does not provide any additional information to the model. An improvement in duplicating examples from the minority class is to synthesize new examples from the minority class. A common technique for this, introduced in this paper, is SMOTE. It’s worth noting that oversampling isn’t our only option, we could for example under-sample (or combine a mix of the two) by using a technique such as TOMEK-links (SMOTE-TOMEK helps do both under and over-sampling in one go). In our case, however, the best performance boost came from SMOTE alone.
Before we do this, however, let's write a general feature processing pipeline to get our data ready for modeling. Our function returns a Sklearn pipeline object that we can use to fit and transform our data. It first splits the data into numeric, categorical features, and binary features as we process each of these differently. The categorical features are encoded using one-hot encoding, while the binary features are left alone. Finally, the numeric features have their missing values imputed. Scaling the numeric features was also tried but it didn’t lead to a performance increase. It’s also in our best interest to not scale these as it makes interpreting the results harder.
from sklearn.preprocessing import StandardScaler, MinMaxScaler, OneHotEncoder, OrdinalEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline, FeatureUnion
from mlxtend.feature_selection import ColumnSelector
from category_encoders import HashingEncoder
def feature_pipeline(config_path="params.yaml"):
"""
:param config_path: path to params.yaml file
:return: preprocessing feature pipeline
"""
# load in config information
config = read_params(config_path)
num_features = config["raw_data_config"]["model_features"]["numeric"]
cat_features = config["raw_data_config"]["model_features"]["categorical"]
binary_features = config["raw_data_config"]["model_features"]["binary"]
# transformers
transforms = []
# categorical pipeline
transforms.append(
(
"categorical",
Pipeline(
[
("select", ColumnSelector(cols=cat_features)),
("encode", OneHotEncoder()),
]
),
)
)
transforms.append(
(
"binary",
Pipeline(
[
("select", ColumnSelector(cols=binary_features)),
("encode", OrdinalEncoder()),
]
),
)
)
# numeric pipeline
transforms.append(
(
"numeric",
Pipeline(
[
("select", ColumnSelector(cols=num_features)),
("impute", SimpleImputer(missing_values=np.nan, strategy="median")),
]
),
)
)
# combine features
features = FeatureUnion(transforms)
return features
A general training function is written below, notice we can choose whether we want to use SMOTE or not. The sampling strategy in SMOTE controls how much we resample the minority class and it’s something we can tune later.
from imblearn.over_sampling import SMOTE, SMOTENC
def train(fold, df, model=LogisticRegression(solver='newton-cg'), smote=False):
"""
:param fold: fold to train model on
:param df: pandas dataframe containing our data
:param model: model to train data on
:param smote: float, if named it is the sampling strategy for SMOTE
:return: f1, recall, precision validation score for fold, as well as y_valid and preds
"""
# feature pipeline
features = feature_pipeline()
# define train and validation set
df_train = df[df.kfold != fold].reset_index(drop=True)
df_valid = df[df.kfold == fold].reset_index(drop=True)
# target and features
y_train = df_train['churn'].values
y_valid = df_valid['churn'].values
# create training and validation features
x_train = features.fit_transform(df_train)
x_valid = features.transform(df_valid)
# smote
if smote:
smt = SMOTE(random_state=42, sampling_strategy=smote)
x_train, y_train = smt.fit_resample(x_train, y_train)
# create and train model
clf = model
clf.fit(x_train, y_train)
preds = clf.predict(x_valid)
# score model
scores = score(y_valid, preds)
return scores, [y_valid, preds]
Before we use SMOTE, let’s train a logistic regression model on all of the features to try and get a new baseline.
f1_scores, recall_scores, precision_scores = [], [], []
for fold in range(5):
scores, _ = train(fold,df, smote=False)
f1, recall, precision = scores
f1_scores.append(f1)
recall_scores.append(recall)
precision_scores.append(precision)
# average scores over each fold
f1_avg = np.average(f1_scores)
recall_avg = np.average(recall_scores)
precision_avg = np.average(precision_scores)
print(f"Average F1 = {f1_avg}, Recall = {recall_avg}, Precision = {precision_avg}")
# log metrics on mlflow
with mlflow.start_run(run_name="lr_all_features") as mlops_run:
mlflow.log_metric("F1", f1_avg)
mlflow.log_metric("Recall", recall_avg)
mlflow.log_metric("Preision", precision_avg)
info
Average F1 = 0.30667, Recall = 0.21075, Precision = 0.57206
The results are definitely better than before but still not great. We’ve waited long enough, let’s try using SMOTE! We are going to use SMOTE to over-sample our churn data points so that we end up with equal class distributions.
def train_and_eval(df, model=LogisticRegression(solver='newton-cg'), smote=0.75, model_name="", params = {}, log_mlflow=True):
'''
train model and evaluate it on each fold
:param df: pandas dataframe containing our data
:param model: model to train data on
:param model_name: string, for tracking on mlflow
:param params: dict, for tracking on mlflow
:param log_mlflow: boolean, if true then log results using mlflow
:return: average score for each metric
'''
f1_scores, recall_scores, precision_scores = [], [], []
for fold in range(5):
scores, _ = train(fold, df, model=model, smote=smote)
f1, recall, precision = scores
f1_scores.append(f1)
recall_scores.append(recall)
precision_scores.append(precision)
# average scores over each fold
f1_avg = np.average(f1_scores)
recall_avg = np.average(recall_scores)
precision_avg = np.average(precision_scores)
print(f"Average F1 = {f1_avg}, Recall = {recall_avg}, Precision = {precision_avg}")
# log metrics on mlflow
if log_mlflow:
with mlflow.start_run(run_name=model_name) as mlops_run:
mlflow.log_metric("F1", f1_avg)
mlflow.log_metric("Recall", recall_avg)
mlflow.log_metric("Preision", precision_avg)
if params:
mlflow.log_params(params)
return f1_avg
An important side note: when using SMOTE we need to evaluate performance on a validation set that has not been over-sampled. Otherwise, we will not be getting a true performance measure.
train_and_eval(df, model_name="lr_all_features_smote")
info
Average F1 = 0.49789, Recall = 0.69068, Precision = 0.38947
Wow! We have boosted the F1 score from 0.31 to 0.50, and the recall has gone from 0.21 to 0.69! An important note is that the precision has practically stayed the same. Why is that? Well, what is precision measuring? Mathematically, precision is the number of true positives divided by the number of true positives plus the number of false positives. It tells us that our model is correct 47% of the time when trying to predict positive samples. So by over-sampling, we have decreased the number of false negatives but we have also increased the number of false positives. This is OK as we decided we will favor false positives over false negatives. An intuitive way to see this change is by looking at a confusion matrix.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# get preds for non-smote and smote models
_, evals = train(0, df, smote=False)
_, evals_smote = train(0, df, smote=True)
# set axis and plot
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(15,10))
ax1.set_title("Model without SMOTE")
ConfusionMatrixDisplay.from_predictions(*evals, ax=ax1)
ax2.set_title("Model with SMOTE")
ConfusionMatrixDisplay.from_predictions(*evals_smote, ax=ax2)
plt.tight_layout()
plt.show()
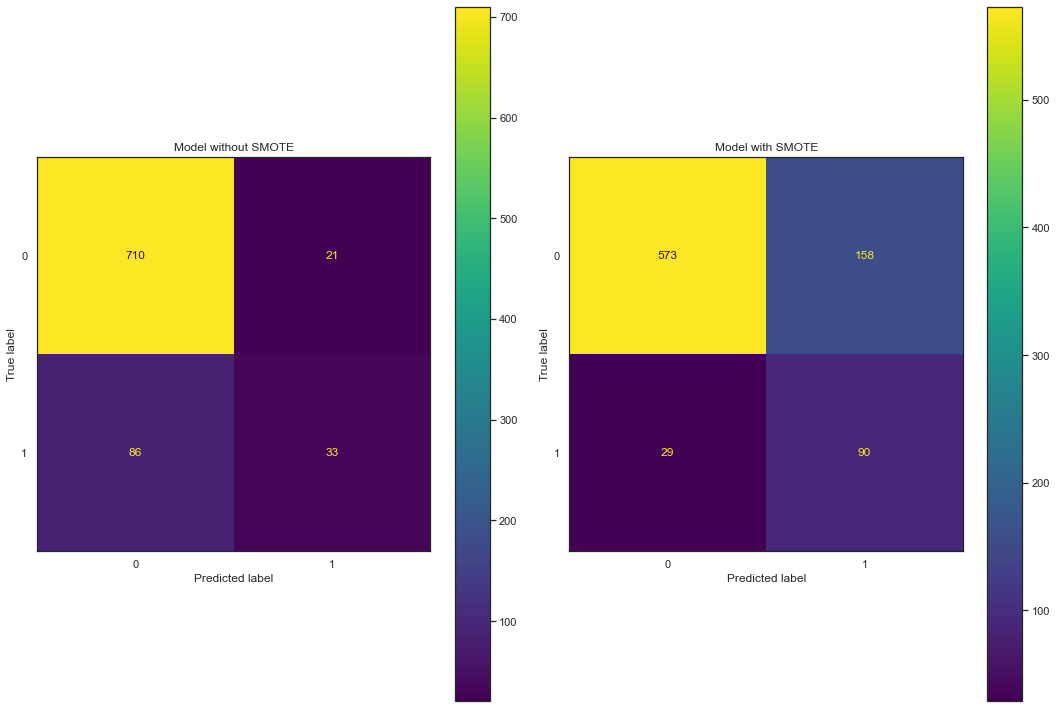
We can see that the TP number goes from 33 to 90 and the FN number goes from 86 to 29, great! However, as a consequence of this, we see the FP number goes from 21 to 158. But, as mentioned earlier, we are ok with that as we care more about finding out which customers are going to leave. A little side note: the FP and FN rates can be tuned using the probability threshold and the easiest way to compare the two models is to compare F1 scores.
Feature Selection
We can train a more complicated model and then use this to select features. Specifically, we train a random forest classifier and then use SHAP values to select the most promising features. Narrowing down the feature space helps reduce dimensionality and generalizability while also making interpreting results easier. It’s a win-win!
from sklearn.ensemble import RandomForestClassifier
features = feature_pipeline()
X = np.asarray(features.fit_transform(df).todense())
y = df['churn'].values
clf = RandomForestClassifier()
model = clf.fit(X,y)
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
shap.summary_plot(shap_values, features=X, feature_names=feature_names, plot_type='bar)
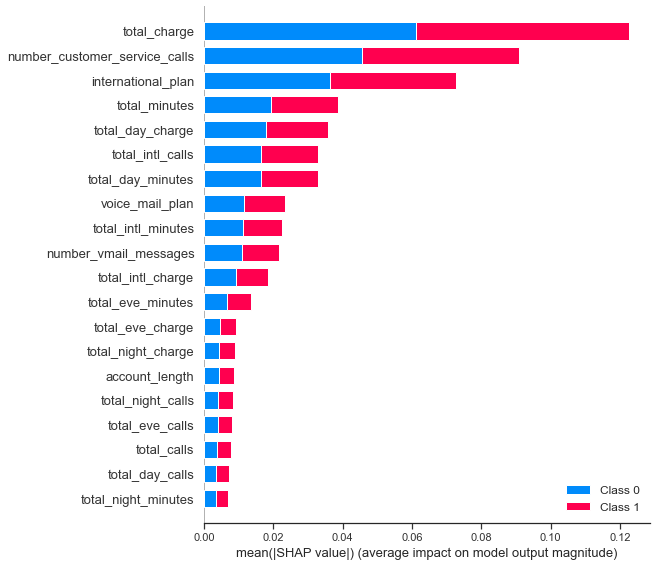
We can now define a new pipeline to preprocess and only select our needed features. With this, let’s see how our logistic regression model does with our narrowed-down features!
train_and_eval(df, model_name="lr_selected_features_smote")
info
Average F1 = 0.50255, Recall = 0.69403, Precision = 0.39407
Awesome, we’ve removed features and our performance increases slightly. This confirms to us that the other features weren’t important.
But can we do better than our logistic regression?
It would be easy here to go all guns blazing and train an XGBOOST model, but remember that is not our goal. Our goal is to build an interpretable model that we can use to try and keep customers from leaving. As well as logistic regression, decision tree classifiers are very interpretable. Let’s see how it gets on.
from sklearn.tree import DecisionTreeClassifier
train_and_eval(df, model=DecisionTreeClassifier(), model_name="dt_selected_features_smote")
info
Average F1 = 0.81529, Recall = 0.84614, Precision = 0.78694
It does well! We need to be very careful though as decision trees overfit like there is no tomorrow. Let’s go ahead and tune hyperparameters on both models to see if we can optimize things a little more. We will use Optuna as I just love how easy and fast it is.
Hyperparameter Tuning
We need a be super careful here, decision trees are very prone to overfitting and this is why random forest models are usually preferred. The random forest can generalize over the data in a better way as the randomized feature selection acts as a form of regularization. As discussed earlier though, in our case we care more about interpretability than performance. Now, although cross-validation is great for seeing how the model is generalizing, it doesn’t necessarily prevent overfitting as we will just end up overfitting the validation sets.
One measure of overfitting is when the training score is much higher than the testing score. I initially tried setting the objective function in the Optuna trial to the cross-validated validation scores but this still lead to overfitting as DTs don’t have much regularization.
Another possibility, that is this case worked superbly, is weighting the difference between cross-validated training scores and validation scores vs the validation score itself. For example, for F1 scores, a possible objective function is
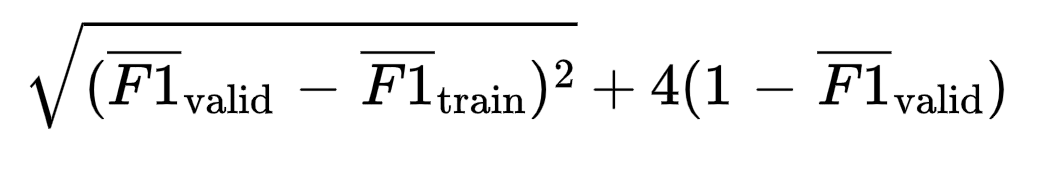
In this case, the RMSE of the difference between validation and training is weighted four times less than the validation F1 score. Optimizing this function forces the train and valid score to stay close, while also maximizing the validation score.
from optuna import Trial, create_study
from optuna.samplers import TPESampler
from scipy.stats import loguniform
def objective(trial, n_jobs=-1, random_state=42):
'''
Objective function to optimize our custom metric using Optuna's TPE sampler
'''
# smote param space
smote_space = {'sampling_strategy': trial.suggest_uniform('sampling_strategy', 0.5, 1)}
# define search spaces
if model == LogisticRegression:
params = {
'solver': trial.suggest_categorical('solver', ['liblinear', 'saga']),
'penalty': trial.suggest_categorical('penalty', ['l1', 'l2']),
'C': trial.suggest_float("C", 1.0, 10.0, log=True),
'tol': trial.suggest_float("tol", 0.0001, 0.01, log=True),
'max_iter': trial.suggest_int('max_iter', 100, 1000)
}
else:
params = {
'max_depth': trial.suggest_int('max_depth',2,10),
'min_samples_leaf': trial.suggest_int('min_samples_leaf',1,30),
'min_samples_split': trial.suggest_int('min_samples_split',2,10),
'criterion': trial.suggest_categorical('criterion', ["gini", "entropy"])
}
# feature pipeline
features = feature_pipeline()
# create training and validation features
X = features.fit_transform(df)
y = df['churn'].values
train_f1, valid_f1 = [], []
# Create StratifiedKFold object.
strat = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
for train_index, test_index in strat.split(X, y):
# split data
x_train, x_valid = X[train_index], X[test_index]
y_train, y_valid = y[train_index], y[test_index]
# feature transformations and smote
smt = SMOTE(random_state=42, **smote_space)
x_train_smt, y_train_smt = smt.fit_resample(x_train, y_train)
# train model
clf = model(**params)
clf.fit(x_train_smt, y_train_smt)
# compute f1 score on valid and training data (without SMOTE!)
preds_train = clf.predict(x_train)
preds_valid = clf.predict(x_valid)
train_f1.append(f1_score(y_train, preds_train))
valid_f1.append(f1_score(y_valid, preds_valid))
# compute mean of f1 train/valid scores
train_f1_mean, valid_f1_mean = np.array(train_f1).mean(), np.array(valid_f1).mean()
# train/test cross score
return train_valid_f1_score(train_f1_mean, valid_f1_mean)
This gives us the following results:
- Logistic Regression Best Hyperparameters: {‘solver’ : ‘liblinear’, ‘penalty’ : ‘l2’, ‘C’ : 1.14, ‘tol’ : 0.0002, max_iter : 150}
- Decision Tree Best Hyperparameters: {‘max_depth’: 7, ‘min_samples_leaf’: 4, ‘min_samples_split’: 10, ‘criterion’: ‘gini’},
- SMOTE Sampling Strategy 0.70 for LR and 0.56 for DT
Let’s train some models with these parameters and see what we get!
info
LOGISTIC REGRESSION: Average training F1 score: 0.50095, Average validation F1 score: 0.50340, Overfit score: 1.98883
DECISION TREE Average training F1 score: 0.91534, Average validation F1 score: 0.89280, Overfit score: 0.45129
Although this model looks great and doesn’t appear to be overfitting we are going to go with the model below that has been tuned with a lower maximum depth. Our goal is interpretability and a depth of 7 doesn’t really give us that. So we are sacrificing a little bit of accuracy for interpretability.
info
Average training F1 score: 0.82174, Average validation F1 score: 0.81610, Overfit score: 0.74122
Great, so we now have a few potential models. We are going to move forward with the decision tree model as the logistic regression model isn’t quite up to scratch.
Pruning the Decision Tree
Although our model doesn’t appear to be overfitting, we are still going to prune the decision tree as it helps us get rid of sub-nodes that don’t have much predictive power. We do this with the hope that this helps our model generalize better. An added bonus, that tends to come with most regularization, is that it also helps improve the interpretability of the model.
We can prune our tree by picking the right cost complexity parameter. We will start by training a model on the whole dataset, with our chosen hyperparams, to find our space of α’s — the cost complexity parameter. We can then score each of these α’s in a cross-validated way to find the best complexity to choose.
We found that the value α = 0.00811411 is the best complexity to choose. In general, as α increases the number of nodes and depth decreases. So we pick the highest α value that still has a good average F1 score.
We can now train our final model!
How Does It Perform on Test Data
def predict(X, clf, feature_pipeline, thresh=0.5):
'''
Predict customer churn on new data
:param X: data containing features
:param clf: trained model
:param feature_pipeline: trained feature processing pipeline
:param thresh: prediction threshold
:return: predictions
'''
X = feature_pipeline.transform(X)
preds = (clf.predict_proba(X)[:,1] >= thresh).astype(int)
return preds
df_test = pd.read_csv("data/external/test.csv")
df_test = preprocess(df_test, target='churn')
y_test = df_test['churn'].values
preds = predict(df_test, clf, features)
f1, recall, precision = score(y_test, preds)
print(f"Average F1 = {f1}, Recall = {recall}, Precision = {precision}")
info
Average F1 = 0.77729, Recall = 0.65925, Precision = 0.94680
The model does well on the test data! We can see that the precision is a lot higher than the recall however but this is something that can be tuned by changing the prediction probability threshold. In our case, we are trying to get to 80% recall while maximizing precision.
Picking the Optimal Probability Threshold
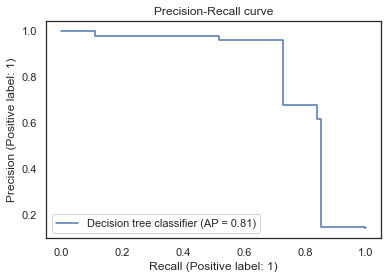
We can now tune the probability threshold to try and optimize our precision-recall trade-off. Let’s plot a precision-recall curve and find the optimal threshold to achieve 80% recall.
from sklearn.metrics import PrecisionRecallDisplay
# training data
x_train = features.transform(df)
y_train = df['churn'].values
# precision recall curve
display = PrecisionRecallDisplay.from_estimator(
clf, x_train, y_train, name="Decision tree classifier"
)
_ = display.ax_.set_title("Precision-Recall curve")
from sklearn.metrics import precision_recall_curve
def optimize_threshold(clf, df, recall = 0.80):
'''
Optimize prob. threshold on training dataset
:param df: pandas dataframe
:param recall: desired recall
:return: optimal prob. threshold
'''
# create features and target labels
X = features.transform(df)
y = df['churn'].values
# get scores for valid data
y_scores = clf.predict_proba(X)[:, 1]
# locate where recall is closest to 0.80
precisions, recalls, thresholds = precision_recall_curve(y, y_scores)
distance_to_optim = abs(recalls - recall)
optimal_idx = np.argmin(distance_to_optim)
thresh = thresholds[optimal_idx]
return thresh
thresh = optimize_threshold(clf, df)
print(thresh)
We get a threshold of 0.426. If we predict on our test set again then hopefully we will see something closer to our desired recall! And yes, I know I’ve committed the cardinal sin of using the test set twice but this was for demonstration purposes. The test set is normally a ‘one and done’ situation. Our final results are:
info
Average F1 = 0.79584, Recall = 0.85185, Precision = 0.74675
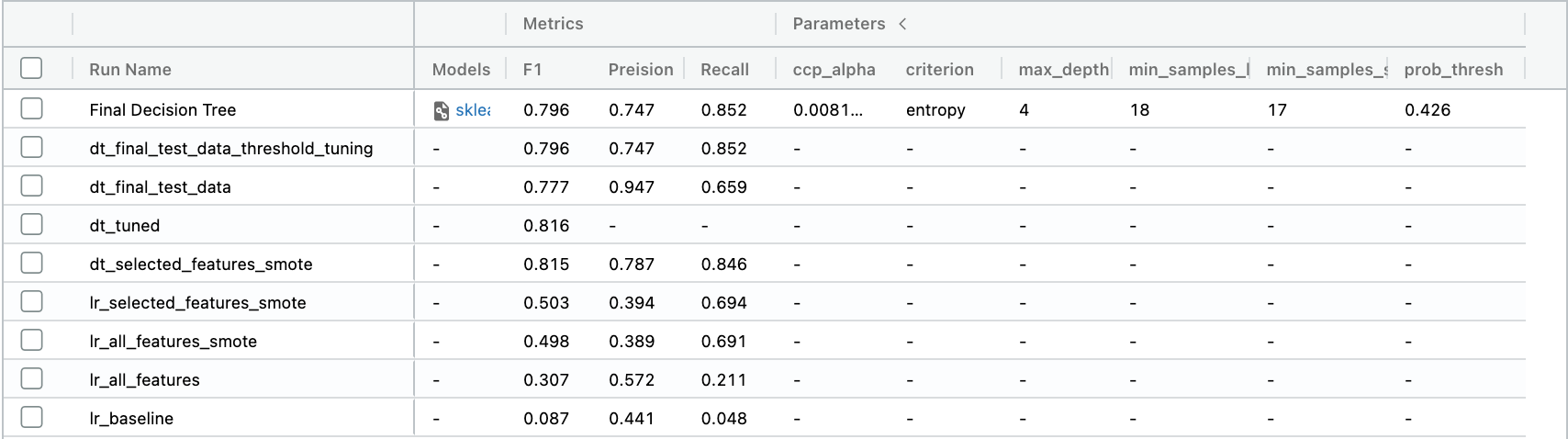
Awesome! We have done what we wanted to do, and things work well! It’s also great to see test scores so similar to our earlier scores as it shows we haven’t overfitted our model. Let’s log this model on MLFLOW.
# log metrics on mlflow
with mlflow.start_run(run_name="Final Decision Tree") as mlops_run:
mlflow.log_metric("F1", f1)
mlflow.log_metric("Recall", recall)
mlflow.log_metric("Preision", precision)
mlflow.log_params(params)
mlflow.log_params({"prob_thresh": 0.426})
# log model and pipeline
mlflow.sklearn.log_model(clf, "clf")
mlflow.sklearn.log_model(features, "features_pipeline")
MLFLOW Experiment Session
Model Interpreting
Tree-based models split the data multiple times according to certain cutoff values in the features. By splitting, different subsets of the dataset are created, where each instance belongs to a certain subset. To predict the outcome in each leaf node, the average outcome of the training data in this node is used.
The interpretation for decision trees is very easy: Starting from the root node, you go to the next nodes and the edges tell you which subsets you are looking at. Once you reach the leaf node, the node tells you the predicted outcome. All the edges are connected by ‘AND’.
So the general way we can predict is: If feature x is smaller (/bigger) than threshold c AND … then the predicted outcome is the most common value of the target of the instances in that node. Let’s plot out the tree and see what we can infer!
# get feature names
numeric_features = [
'total_charge', 'number_customer_service_calls', 'total_day_minutes', 'total_day_charge',
'total_minutes', 'total_intl_calls', 'total_intl_minutes', 'number_vmail_messages', 'total_intl_charge'
]
binary_features = ['international_plan', 'voice_mail_plan']
feature_names = np.append(numeric_features, binary_features)
# plot tree from our model
import graphviz
from sklearn import tree
tree_graph = tree.export_graphviz(clf, out_file=None,
feature_names=feature_names,
class_names=['No churn', 'Churn'],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(tree_graph)
graph
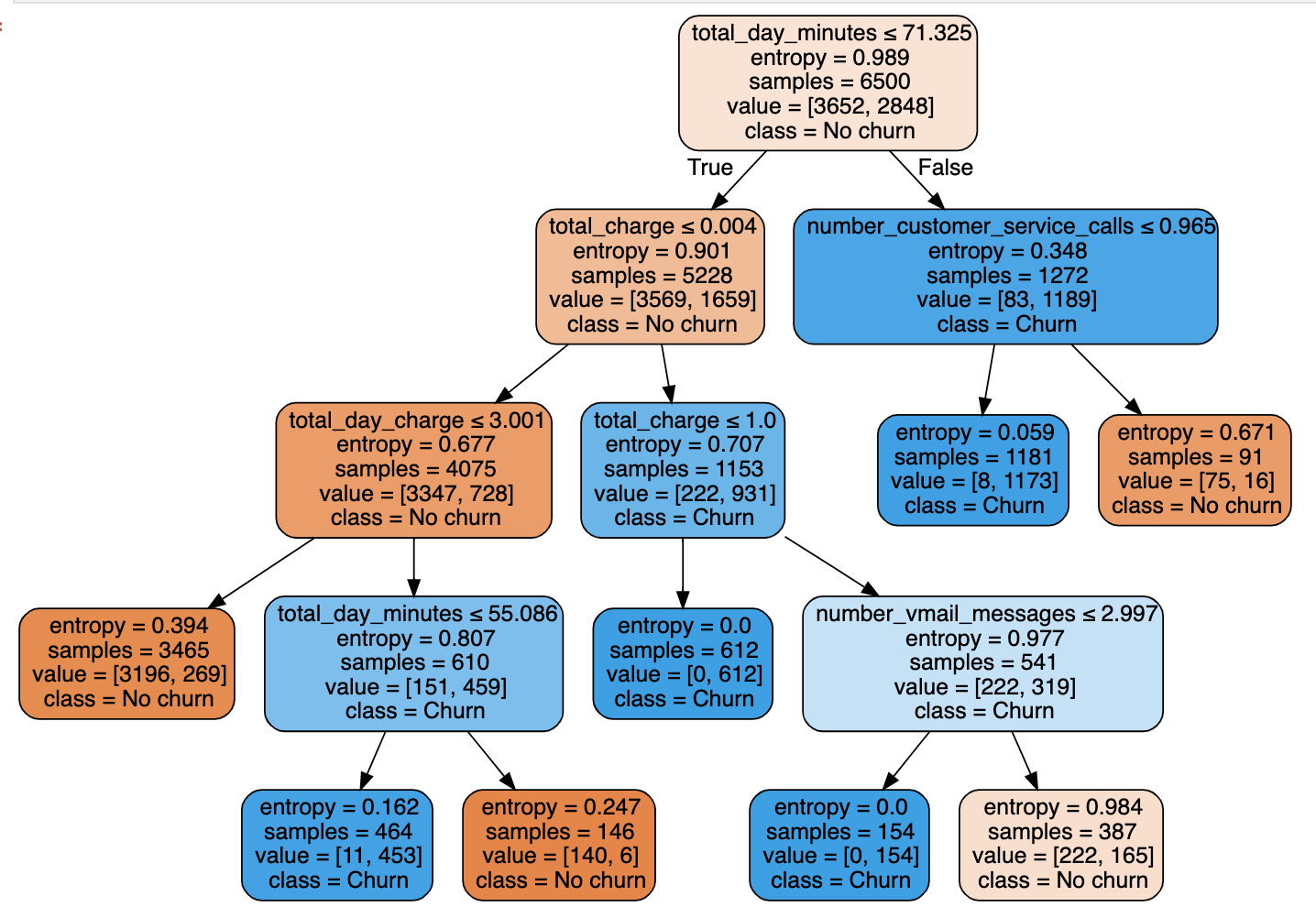
Each node in the tree will give a condition and the left node below is True and the right node is False. The first split was performed with the total day minutes feature, which counts the total minutes of all calls made in the day. We can see for example that if the total minutes are less than 71 we follow the tree left and if the minutes are greater than 71 we go right.
Each prediction from the tree is made by following the tree down until a root node is hit. For example, if a customer has less than 71 total day minutes and their total charge is between 0.04 and 1 then we would predict them to churn.
We can see that the charge from the telecom provider seems to be a big distinguishing factor between customers and this is confirmed by the SHAP feature importance plot earlier. By following the tree left we can see that customers with a high day charge but low day minutes tend to churn more than stay. If the day charge is less than 3 however, the customers tend to stay no matter what the minutes are! One possible explanation for this could be that the customers churning are on mobile plans that don’t correctly suit their needs, this would need to be investigated further though.
Another interesting observation is that if a customer has a high total day minute (>71) and they do not speak to customer service (<0.965 calls i.e. no calls) they are more likely to churn than customers that do speak to customers service. Again, this would need further investigation to draw conclusions as to why this is true. As with most data problems, it quite often leads to more questions to be answered!
Conclusion
We have built an interpretable machine learning model that can identify customers that are likely to churn with our desired recall of 80% (we actually achieved 85% on the test set) and a precision of 75%. That is we identify 85% of the churned customers correctly and 75% of our churn predictions are accurate. Using this model we can then understand the key factors driving customers to leave and hopefully we can use this to try and keep more customers in the long run.
Thanks for reading and I hope you enjoyed it. If you have any comments or questions please feel free to reach out.