
EtLT of my own Strava data using the Strava API, MySQL, Python, S3, Redshift, and Airflow
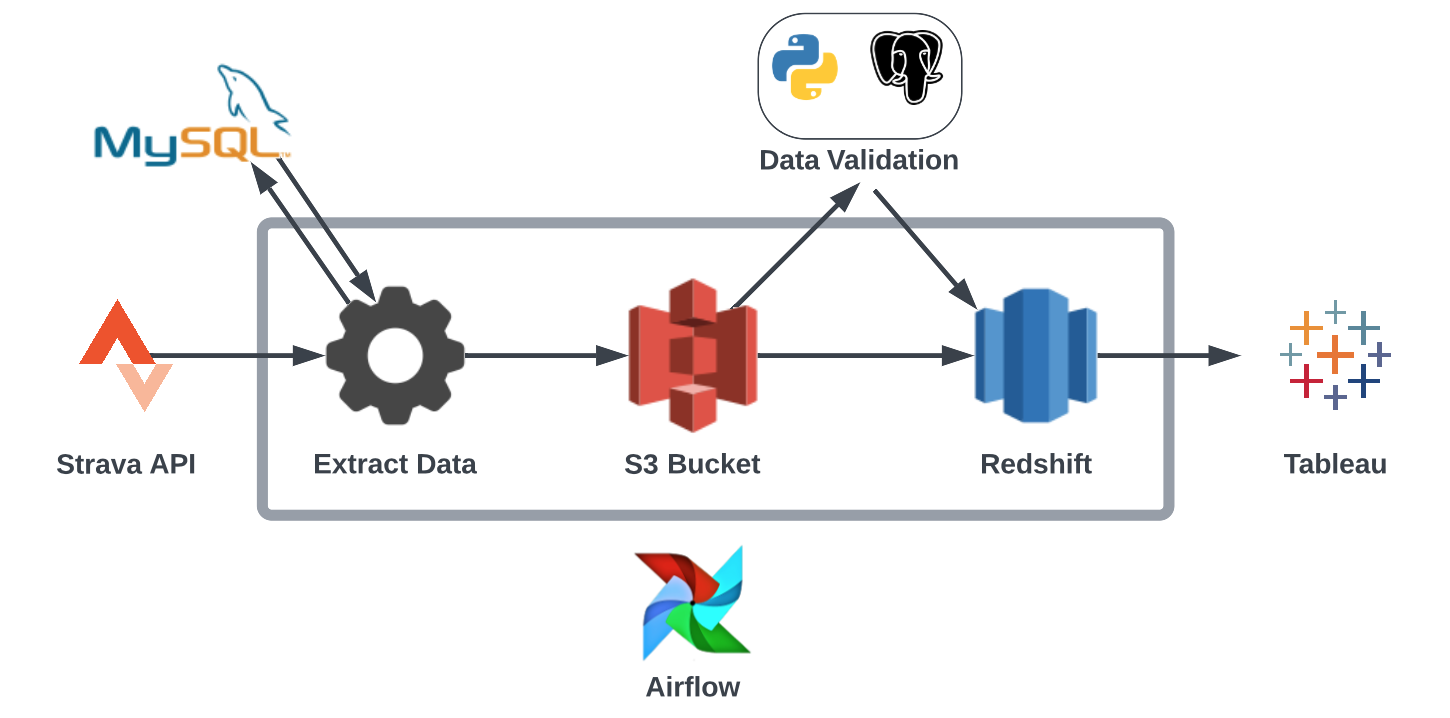
I build an EtLT pipeline to ingest my Strava data from the Strava API and load it into a Redshift data warehouse. This pipeline is then run once a week using Airflow to extract any new activity data. The end goal is then to use this data warehouse to build an automatically updating dashboard in Tableau and also to trigger automatic re-training of my Strava Kudos Prediction model.
Data Extraction
My Strava activity data is first ingested incrementally using the Strava API and loaded into an S3 bucket. On each ingestion run, we query a MySQL database to get the date of the last extraction:
def get_date_of_last_warehouse_update() -> Tuple[datetime, str]:
"""
Get the datetime of last time data was extracted from Strava API
by querying MySQL database and also return current datetime.
"""
mysql_conn = connect_mysql()
get_last_updated_query = """
SELECT COALESCE(MAX(LastUpdated), '1900-01-01')
FROM last_extracted;"""
mysql_cursor = mysql_conn.cursor()
mysql_cursor.execute(get_last_updated_query)
result = mysql_cursor.fetchone()
last_updated_warehouse = datetime.strptime(result[0], "%Y-%m-%d %H:%M:%S")
current_datetime = datetime.today().strftime("%Y-%m-%d %H:%M:%S")
return last_updated_warehouse, current_datetime
We then make repeated calls to the REST API using the requests library until we have all activity data between now and last_updated_warehouse. We include a time.sleep() command to comply with Strava's set rate limit of 100 requests/15 minutes. We also include try: except: blocks to combat
missing data on certain activities.
def make_strava_api_request(
header: Dict[str, str], activity_num: int = 1
) -> Dict[str, str]:
"""Use Strava API to get recent page of new data."""
param = {"per_page": 1, "page": activity_num}
api_response = requests.get(
"https://www.strava.com/api/v3/athlete/activities", headers=header, params=param
).json()
response_json = api_response[0]
return response_json
def extract_strava_activities(last_updated_warehouse: datetime) -> List[List]:
"""Connect to Strava API and get data up until last_updated_warehouse datetime."""
header = connect_strava()
all_activities = []
activity_num = 1
# while activity has not been extracted yet
while True:
# Strava has a rate limit of 100 requests every 15 mins
if activity_num % 75 == 0:
print("Rate limit hit, sleeping for 15 minutes...")
time.sleep(15 * 60)
try:
response_json = make_strava_api_request(header, activity_num)
# rate limit has exceeded, wait 15 minutes
except KeyError:
print("Rate limit hit, sleeping for 15 minutes...")
time.sleep(15 * 60)
response_json = make_strava_api_request(header, activity_num)
date = response_json["start_date"]
if date > last_updated_warehouse:
activity = parse_api_output(response_json)
all_activities.append(activity)
activity_num += 1
else:
break
return all_activities
Before exporting the data locally into a flat pipe-delimited .csv file, we perform a few minor transformations such as formatting dates and timezone columns. Hence the little 't' in EtLT! After we save the data, it is then uploaded to an S3 bucket for later loading into the data warehouse.
def save_data_to_csv(all_activities: List[List]) -> str:
"""Save extracted data to .csv file."""
todays_date = datetime.today().strftime("%Y_%m_%d")
export_file_path = f"strava_data/{todays_date}_export_file.csv"
with open(export_file_path, "w") as fp:
csvw = csv.writer(fp, delimiter="|")
csvw.writerows(all_activities)
return export_file_path
def upload_csv_to_s3(export_file_path: str) -> None:
"""Upload extracted .csv file to s3 bucket."""
s3 = connect_s3()
s3.upload_file(export_file_path, "strava-data-pipeline", export_file_path)
Finally, we execute a query to update the MySQL database on the last date of extraction.
def save_extraction_date_to_database(current_datetime: datetime) -> None:
"""Update last extraction date in MySQL database to todays datetime."""
mysql_conn = connect_mysql()
update_last_updated_query = """
INSERT INTO last_extracted (LastUpdated)
VALUES (%s);"""
mysql_cursor = mysql_conn.cursor()
mysql_cursor.execute(update_last_updated_query, current_datetime)
mysql_conn.commit()
Data Loading
Once the data is loaded into the S3 data lake it is then loaded into our Redshift data warehouse. We load the data in two parts:
- We first load the data from the S3 bucket into a staging table with the same schema as our production table
- We then perform validation tests between the staging table and the production table (see here). If all critical tests pass we then remove all duplicates between the two tables by first deleting them from the production table. The data from the staging table is then fully inserted into the production table.
def copy_to_redshift_staging(table_name: str, rs_conn, s3_file_path: str, role_string: str) -> None:
"""Copy data from s3 into Redshift staging table."""
# write queries to execute on redshift
create_temp_table = f"CREATE TABLE staging_table (LIKE {table_name});"
sql_copy_to_temp = f"COPY staging_table FROM {s3_file_path} iam_role {role_string};"
# execute queries
cur = rs_conn.cursor()
cur.execute(create_temp_table)
cur.execute(sql_copy_to_temp)
rs_conn.commit()
def redshift_staging_to_production(table_name: str, rs_conn) -> None:
"""Copy data from Redshift staging table to production table."""
# if id already exists in table, we remove it and add new id record during load
delete_from_table = f"DELETE FROM {table_name} USING staging_table WHERE '{table_name}'.id = staging_table.id;"
insert_into_table = f"INSERT INTO {table_name} SELECT * FROM staging_table;"
drop_temp_table = "DROP TABLE staging_table;"
# execute queries
cur = rs_conn.cursor()
cur.execute(delete_from_table)
cur.execute(insert_into_table)
cur.execute(drop_temp_table)
rs_conn.commit()
Data Validation
We implement a simple framework in python that is used to execute SQL-based data validation checks in our data pipeline. Although it lacks many features we would expect to see in a production environment, it is a good start and provides some insight into how we can improve our infrastructure.
The validatior.py script executes a pair of SQL scripts on Redshift and compares the two based on a comparison operator (>, <, =). The test then passes or fails based on the outcome of the two executed scripts. We execute this validation step after we upload our newly ingested data to the staging table but before we insert this table into the production table.
def execute_test(db_conn, script_1: str, script_2: str, comp_operator: str) -> bool:
"""
Execute test made up of two scripts and a comparison operator
:param comp_operator: comparison operator to compare script outcome
(equals, greater_equals, greater, less_equals, less, not_equals)
:return: True/False for test pass/fail
"""
# execute the 1st script and store the result
cursor = db_conn.cursor()
sql_file = open(script_1, "r")
cursor.execute(sql_file.read())
record = cursor.fetchone()
result_1 = record[0]
db_conn.commit()
cursor.close()
# execute the 2nd script and store the result
...
print("Result 1 = " + str(result_1))
print("Result 2 = " + str(result_2))
# compare values based on the comp_operator
if comp_operator == "equals": return result_1 == result_2
elif comp_operator == "greater_equals": return result_1 >= result_2
...
# tests have failed if we make it here
return False
As a starting point, I implemented checks that check for duplicates, compare the distribution of the total activities in the staging table (Airflow is set to execute at the end of each week) to the average historical weekly activity count, and compare the distribution of the Kudos Count metric to the historical distribution using the z-score. In other words, the last two queries check if the values are within a 90% confidence interval in either direction of what's expected based on history. For example, the following query computes the z-score for the total activities uploaded in a given week (found in the staging table).
with activities_by_week AS (
SELECT
date_trunc('week', start_date::date) AS activity_week,
COUNT(*) AS activity_count
FROM public.strava_activity_data
GROUP BY activity_week
ORDER BY activity_week
),
activities_by_week_statistics AS (
SELECT
AVG(activity_count) AS avg_activities_per_week,
STDDEV(activity_count) AS std_activities_per_week
FROM activities_by_week
),
staging_table_weekly_count AS (
SELECT COUNT(*) AS staging_weekly_count
FROM staging_table
),
activity_count_zscore AS (
SELECT
s.staging_weekly_count AS staging_table_count,
p.avg_activities_per_week AS avg_activities_per_week,
p.std_activities_per_week as std_activities_per_week,
--compute zscore for weekly activity count
(staging_table_count - avg_activities_per_week) / std_activities_per_week AS z_score
FROM staging_table_weekly_count s, activities_by_week_statistics p
)
SELECT ABS(z_score) AS two_sized_zscore
FROM activity_count_zscore;
By running
python src/validator.py sql/validation/weekly_activity_count_zscore.sql sql/validation/zscore_90_twosided.sql.sql greater_equals warn`
in the terminal we compare this z-score found in the previous query to the 90% confidence interval z-score SELECT 1.645;. The 'warn' at the end of the command tells the script not to exit with an error but to warn us instead. On the other hand, if we add 'halt' to the end the script will exit with an error code and halt all further downstream tasks.
We also implement a system to send a notification to a given Slack channel with the validation test results, this validation system was inspired by the Data Validation in Pipelines chapter of James Densmore's excellent Data Pipelines book.
def send_slack_notification(webhook_url: str, script_1: str, script_2: str,
comp_operator: str, test_result: bool) -> bool:
try:
if test_result == True:
message = (f"Validation Test Passed!: {script_1} / {script_2} / {comp_operator}")
else:
message = (f"Validation Test FAILED!: {script_1} / {script_2} / {comp_operator}")
# send test result to Slack
slack_data = {"text": message}
response = requests.post(webhook_url, data=json.dumps(slack_data),
headers={"Content-Type": "application/json"})
# if post request to Slack fails
if response.status_code != 200:
print(response)
return False
except Exception as e:
print("Error sending slack notification")
print(str(e))
return False
We then combine all the tests to a shell script validate_load_data.sh that we run after loading the data from the S3 bucket to a staging table but before we insert this data into the production table. Running this pipeline on last week's data gives us the following output:
 It's great to see that our second test failed because I didn't run anywhere near as much last week as I usually do!
It's great to see that our second test failed because I didn't run anywhere near as much last week as I usually do!
Although this validation framework is very basic, it is a good foundation that can be built upon at a later date.
Data Transformations
Now the data has been ingested into the data warehouse, the next step in the pipeline is data transformations. Data transformations in this case include both non-contextual manipulation of the data and modeling of the data with context and logic in mind. The benefit of using the ELT methodology instead of the ETL framework, in this case, is that it gives us, the end-user, the freedom to transform the data the way we need as opposed to having a fixed data model that we cannot change (or at least not change without hassle). In my case, I am connecting my Redshift data warehouse to Tableau building out a dashboard. We can, for example, build a data model to extract monthly statistics:
CREATE TABLE IF NOT EXISTS activity_summary_monthly (
activity_month numeric,
...
std_kudos real
);
TRUNCATE activity_summary_monthly;
INSERT INTO activity_summary_monthly
SELECT EDATE_TRUNC('month', start_date::date) AS activity_month,
ROUND(SUM(distance)/1609) AS total_miles_ran,
...
ROUND(STDDEV(kudos_count), 1) AS std_kudos
FROM public.strava_activity_data
WHERE type='Run'
GROUP BY activity_month
ORDER BY activity_month;
We can also build more complicated data models. For example, we can get the week-by-week percentage change in total weekly kudos broken down by workout type:
WITH weekly_kudos_count AS (
SELECT DATE_TRUNC('week', start_date::date) AS week_of_year,
workout_type,
SUM(kudos_count) AS total_kudos
FROM public.strava_activity_data
WHERE type = 'Run' AND DATE_PART('year', start_date) = '2022'
GROUP BY week_of_year, workout_type
),
weekly_kudos_count_lag AS (
SELECT *,
LAG(total_kudos) OVER(PARTITION BY workout_type ORDER BY week_of_year)
AS previous_week_total_kudos
FROM weekly_kudos_count
)
SELECT *,
COALESCE(ROUND(((total_kudos - previous_week_total_kudos)/previous_week_total_kudos)*100),0)
AS percent_kudos_change
FROM weekly_kudos_count_lag;
A further direction to take this would be to utilize a 3rd party tool such as dbt to implement data modeling.
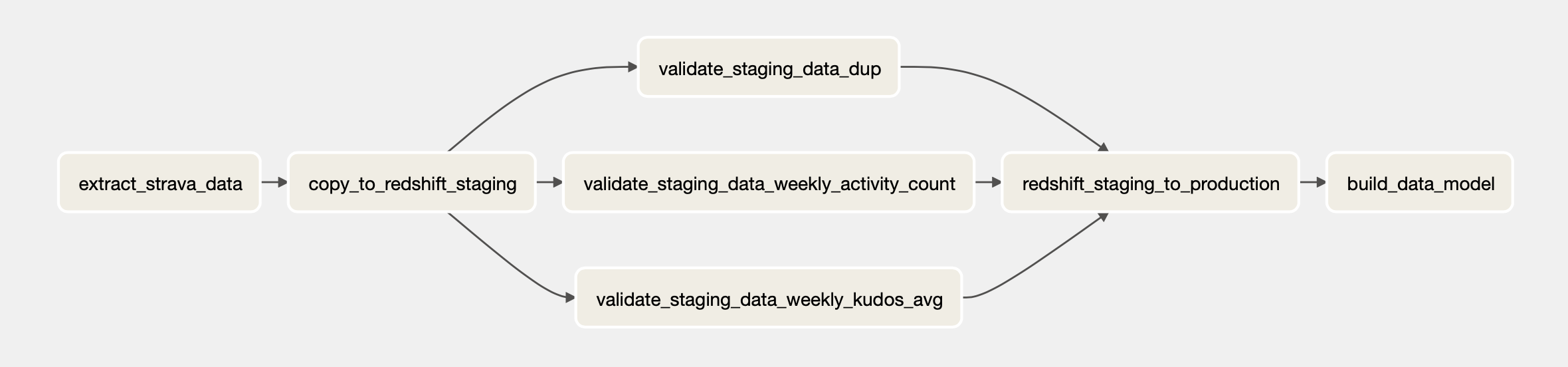
Putting it All Together with Airflow
We create a DAG to orchestrate our data pipeline. We set the pipeline to run weekly which means it will run once a week at midnight on Sunday morning. As seen in the diagram below, our DAG will:
- First, extract any recent data using the Strava API and upload it to an S3 bucket
- It will then load this data into a staging table in our Redshift cluster
- The 3 validation tests will then be executed, messaging our Slack channel the results
- The staging table will then be inserted into the production table, removing any duplicates in the process
- Finally, a monthly aggregation data model will be created in a new table
activity_summary_monthly
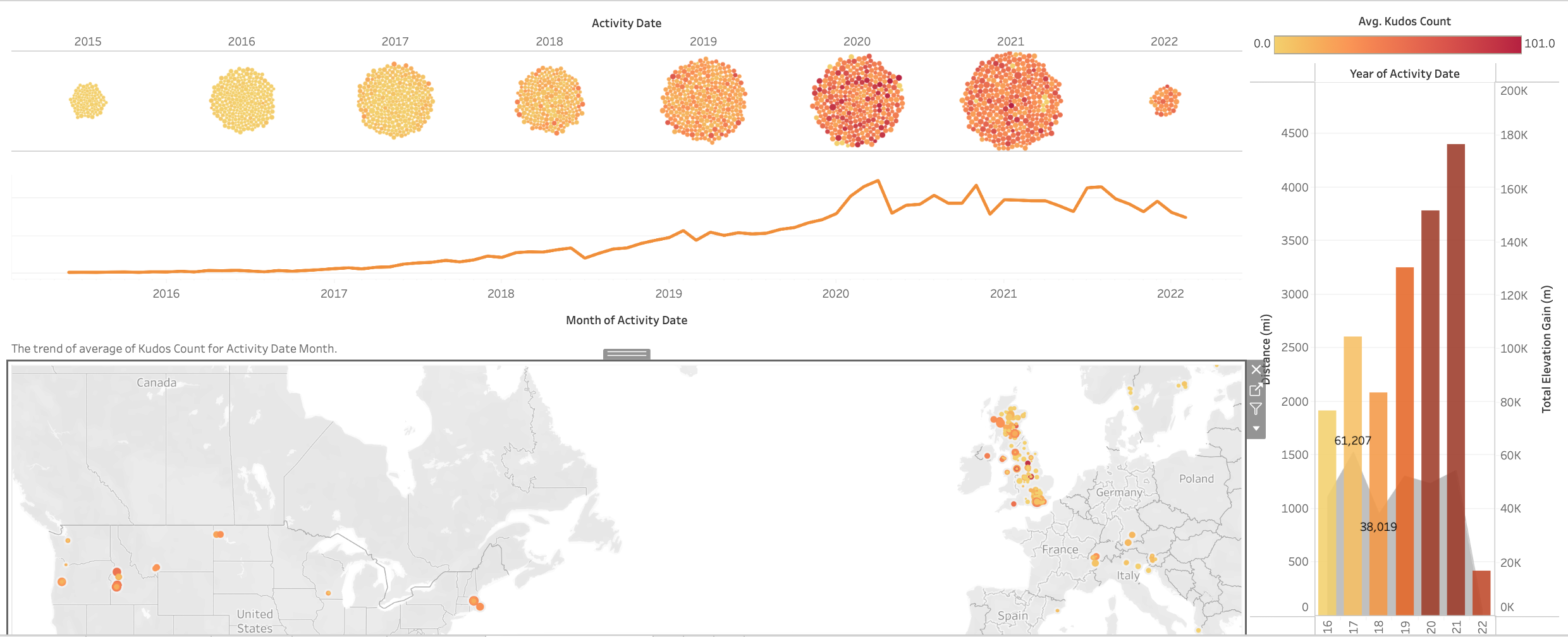
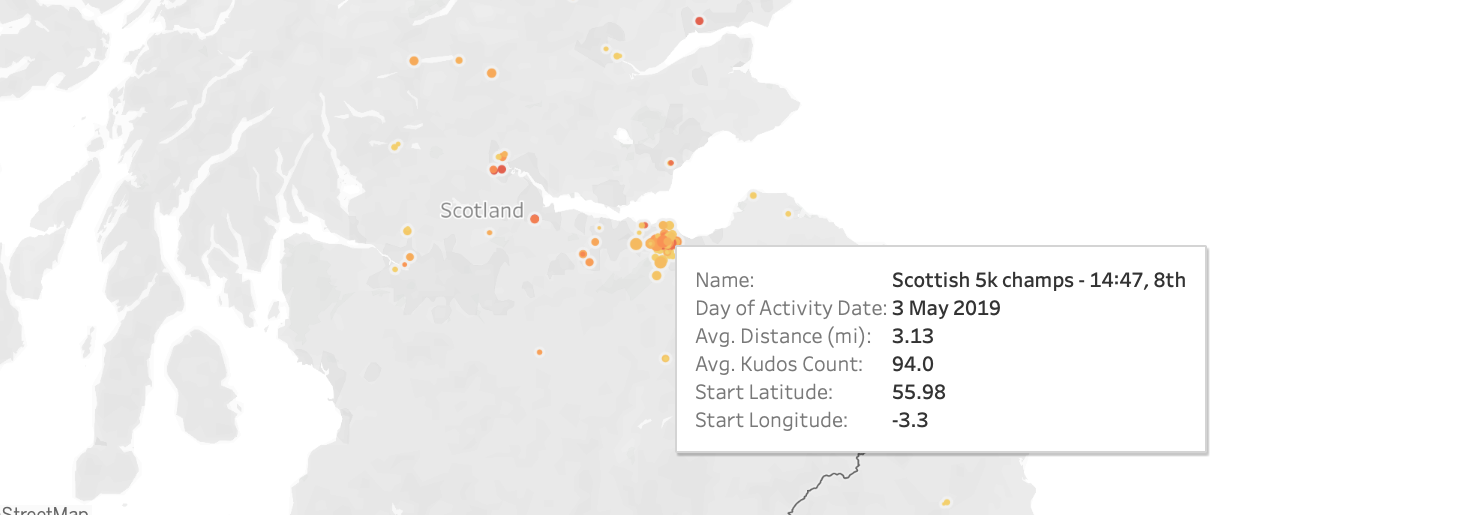
Data Visualization
With the data transformations done we were then able to build out an interactive dashboard using Tableau that updates automatically when new data gets ingested to the data warehouse, which is weekly. The dashboard I created was built to investigate how Kudos on my Strava activities changes over time and location. After building this project I shut down the Redshift server to not incur any costs but a screenshot of the dashboard can be seen below.
Unit Testing
Unit testing was performed using PyTest and all tests can be found in the tests directory. For example, below we see a unit test to test the make_strava_api_request function. It asserts that a dictionary response is received and also that the response contains an 'id' key that is an integer.
@pytest.mark.filterwarnings("ignore::urllib3.exceptions.InsecureRequestWarning")
def test_make_strava_api_request():
header = connect_strava()
response_json = make_strava_api_request(header=header, activity_num=1)
assert "id" in response_json.keys(), "Response dictionary does not contain id key."
assert isinstance(response_json, dict), "API should respond with a dictionary."
assert isinstance(response_json["id"], int), "Activity ID should be an integer."
Further Directions and Considerations
Improve Airflow with Docker: I could have used the docker image of Airflow to run the pipeline in a Docker container which would've made things more robust. This would also make deploying the pipeline at scale much easier!
Implement more validation tests: For a real production pipeline, I would implement more validation tests all through the pipeline. I could, for example, have used an open-source tool like Great Expectations.
Simplify the process: The pipeline could probably be run in a much simpler way. An alternative could be to use Cron for orchestration and PostgreSQL or SQLite for storage.
Data streaming: To keep the Dashboard consistently up to date we could benefit from something like Kafka.