Predicting customer churn from a telecom provider
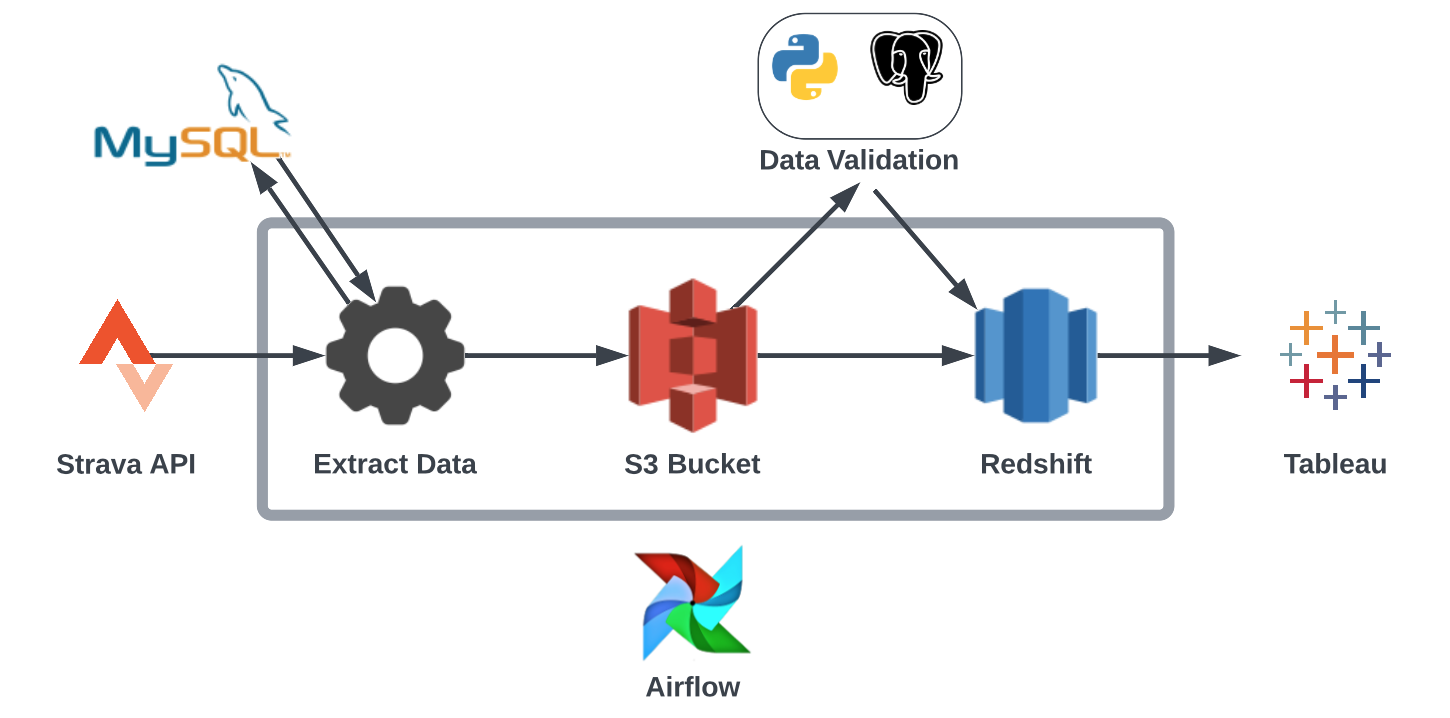
I’ve always believed that to truly learn data science you need to practice data science and I wanted to do this project to practice working with imbalanced classes in classification problems. This was also a perfect opportunity to start working with mlflow to help track my machine learning experiments: it allows me to track the different models I have used, the parameters I’ve trained with, and the metrics I’ve recorded.
This project was aimed at predicting customer churn using the telecommunications data found on Kaggle (which is a publicly available synthetic dataset). That is, we want to be able to predict if a given customer is going the leave the telecom provider based on the information we have on that customer. Now, why is this useful? Well, if we can predict which customers we think are going to leave before they leave then we can try to do something about it! For example, we could target them with specific offers, and maybe we could even use the model to provide us insight into what to offer them because we will know, or at least have an idea, as to why they are leaving.